Data Preprocessing: Denn Automatisierung und KI brauchen gute Daten
Automatisierung kann manuellen Aufwand um mehr als die Hälfte senken – aber nur mit sauberen, strukturierten Daten. Damit auch das keine Arbeit macht, macht Knots fast jeden Input in Sekunden AI- und automatisierungsbereit.
95%
Genauigkeit
>30 Mio.
Tickets mit strukturierten Daten angereichert
1000e Stunden
durch automatisches Preprocessing gespart
80% weniger Aufwand
durch intelligente Datenextraktion und -aufbereitung
70% der Anfragen
automatisiert dank strukturierter Daten
Data Preprocessing: Bereit für Automatisierung und KI
Was ist Data Preprocessing?
Data Preprocessing bedeutet, rohe, unsaubere oder unstrukturierte Inputs in saubere, strukturierte und nutzbare Daten umzuwandeln. Dazu gehören Techniken wie Data Cleaning, Normalisierung, Transformation und Feature Extraction.
Preprocessing ist die Grundlage für jedes automatisierte System, jede Data Pipeline und jedes KI-Modell. Mehr über Data Preprocessing erfahren.
Unstrukturierte Daten strukturieren
Warum Preprocessing für Automatisierung entscheidend ist: Die meisten Daten aus dem echten Leben – E-Mails, Dokumente, Screenshots – sind nicht bereit für Automatisierungen, so gehen wichtige Informationen in PDFs, Freitext oder Anhängen unter.
Mit Knots wandelt ihr sie in strukturierte Formate um – für schnellere Workflows, besseren Support und verlässliche KI.
Beispiel Kundenservice: Die meisten Daten müssen manuell extrahiert werden: Agents laden Anhänge herunter, öffnen sie, suchen Infos und kopieren sie oder tippen alles ab. Langwierig, nervig und fehleranfällig.
Und aus Stunden werden Sekunden
❌ Ohne Preprocessing
- Manuelle Datenarbeit dauert.
- Daten verstecken sich in PDFs oder Freitext.
- Automatisierungen laufen ins Leere oder hängen sich auf.
- Inkonsistenter Input lässt den Workflow Scheitern.
✅ Mit Preprocessing
- saubere, strukturierte Daten in allen Systemen
- Automatisierungen greifen
- KI bekommt sinnvollen Input.
- Agents sparen Zeit wie Nerven und vermeiden Fehler.
Preprocessing spart Zeit, Geld und Nerven
Ob ihr Tickets in Zendesk bearbeitet oder Backend-Systeme synchronisiert: Manuelle Datenarbeit verursacht echte Kosten.
Knots automatisiert diese Schritte – vom Parsen der Anhänge bis zum Füllen der Ticket-Felder – für mehr Tempo und Konsistenz.
First Reply Time um bis zu 45% senken
Automatisierungsbereite Daten bedeuten schnellere Workflows und weniger Wartezeit für eure Kunden.
Bis zu 65% weniger Betriebskosten
Wenn manuelles Extrahieren und Strukturieren wegfällt, kann sich euer Team auf das konzentrieren, was wirklich zählt.
Support skalieren ohne neue Stellen
Mit Preprocessing automatisiert ihr bis zu 75 % eurer Aufgaben und bearbeitet mehr Tickets mit denselben Ressourcen.
Genauigkeit erhöhen und Fehler vermeiden
Strukturierte, validierte Inputs minimieren menschliche Fehler und machen Prozesse zuverlässiger.
Daten für KI-Tools und Analytics vorbereiten
Gut aufbereitete Inputs sind die Grundlage für erfolgreiche Automatisierung und Machine-Learning-Workflows.
Echte Ergebnisse
Knots Preprocessing hat die manuelle Abrechnungsarbeit um bis zu 75 % reduziert und geholfen, ohne mehr Headcount zu wachsen.
 „Vor Knots hat unser Team Aufgaben unter Zeitdruck erledigt, was zu Fehlern und Verzögerungen geführt hat. Jetzt automatisiert das System die Aufgabenverteilung, das Bearbeiten von Dokumenten und sogar Abrechnungen. Wir haben 25 % unserer E-Mails und 65–75 % der Abrechnungen automatisiert und sind gewachsen, ohne die Einarbeitungszeit zu verlängern. So können wir uns auf das Gewinnen und Halten von Kunden konzentrieren. Der praktische Support und die Entwicklungsexpertise vom Knots-Team waren entscheidend für unseren Erfolg.“
„Vor Knots hat unser Team Aufgaben unter Zeitdruck erledigt, was zu Fehlern und Verzögerungen geführt hat. Jetzt automatisiert das System die Aufgabenverteilung, das Bearbeiten von Dokumenten und sogar Abrechnungen. Wir haben 25 % unserer E-Mails und 65–75 % der Abrechnungen automatisiert und sind gewachsen, ohne die Einarbeitungszeit zu verlängern. So können wir uns auf das Gewinnen und Halten von Kunden konzentrieren. Der praktische Support und die Entwicklungsexpertise vom Knots-Team waren entscheidend für unseren Erfolg.“
– Nancy, Liberty Debt Relief
So funktioniert Data Preprocessing mit Knots
Unsere Apps ziehen Informationen aus Dokumenten, E-Mails, Spreadsheets und Bildern und wandeln sie in strukturierte Formate für automatisierte Workflows und KI-Tools um.
Gebaut für Zendesk, einsetzbar weit darüber hinaus.
Ob ticketbasiertes System, CRM oder Dokumentenmanagement: Knots macht eure Daten bereit für Automatisierung und KI.
Sprecht mit uns über euren Use Case!
PDFs, Bilder und Scans mit OCR auslesen
Die meisten Tools scheitern an Bildern, Scans oder Screenshots. Unseres nicht – und das mit einer Genauigkeit, die ihresgleichen sucht. Der OCR Scanner extrahiert alle Daten aus PDFs, Fotos und bildbasierten Anhängen (auch aus handgeschriebenen Notizen) mit erstklassiger Texterkennung. Wo andere Details übersehen, holen wir sie zuverlässig heraus.
Genau das macht Preprocessing auch dann möglich, wenn der Input kein Text ist – und sorgt für präzise Automatisierung über alle Dateiformate hinweg.
Extrahiert und strukturiert Excel-Daten
Macht Word-Dokumente automatisierungs-ready
Zieht texte und Bilder aus Microsoft-Word-Dateien – selbst wenn der Inhalt unstrukturiert ist oder aus einer Mischung aus Tabellen, Absätzen und Bildern besteht.
Damit werden Tickets und Ticket-Felder gefüllt, Workflows getriggert und Daten mit andern Systemen synchronisiert. Kombiniert es mit OCR, um auch gescannte oder bildbasierte Inhalte aus Word-Dokumenten weiter zu verarbeiten.
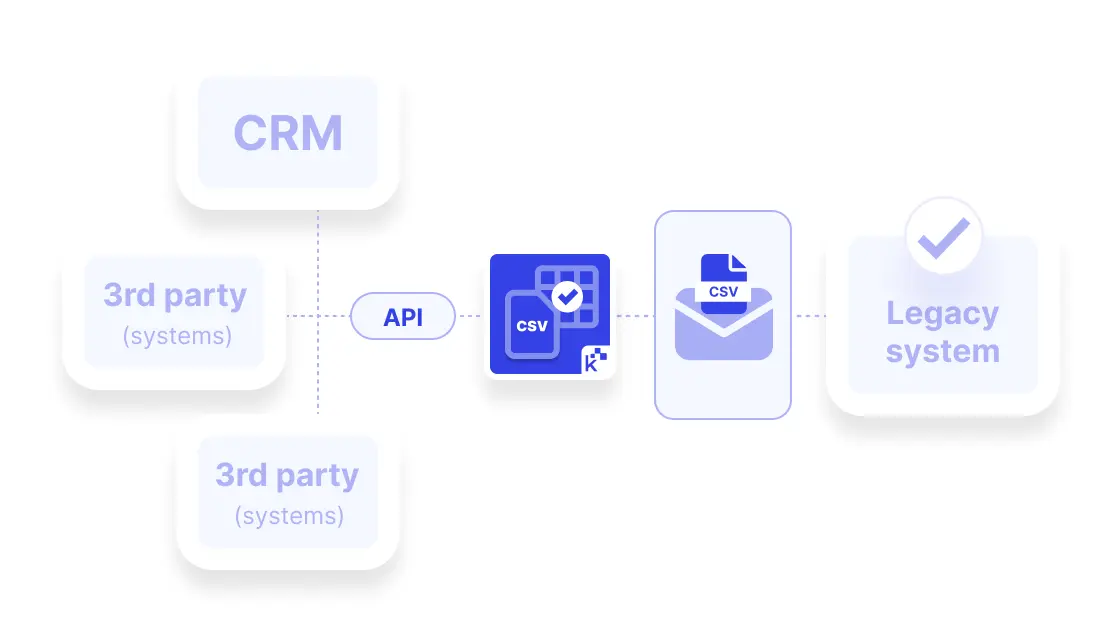
Macht strukturierte Daten aus CSV-Dateien

Für Vertrauen gemacht
Sicher, compliant und enterprise-ready
Wir arbeiten täglich mit sensiblen Daten und komplexen Systemen. Deshalb stehen Sicherheit und Skalierbarkeit im Zentrum jeder Knots-Lösung.
Wir speichern Kundendaten nie – und verarbeiten nur, was nötig ist.



Data Preprocessing in der Praxis
Teams nutzen Knots, um Daten aus jedem Dateiformat zu extrahieren, zu bereinigen und zu strukturieren – und um Aktionen über Systeme hinweg zu automatisieren. Hier sind ein paar Probleme, die unsere Kunden täglich damit lösen.
📊 Excel- und CSV-Anhänge verarbeiten
Zieht Zeilen, Spalten und Zellen aus Spreadsheets, um Tickets zu aktualisieren, Bestände zu synchronisieren oder Anfragen anhand strukturierter Daten zu routen.📄Dokumentendaten extrahieren und Tickets automatisch aktualisieren
Holt Namen, Adressen, Seriennummern oder Bestelldaten aus gescannten Formularen oder hochgeladenen DOCX-Dateien – ohne Copy-Paste.
🔧 Garantie- und Bestellprüfungen automatisieren
Extrahiert Produktdetails aus Rechnungen oder Lieferscheinen – auch aus gescannten PDFs – und prüft Garantie- oder Bestellstatus sofort.🧹 Unsaubere Inputs bereinigen und standardisieren
Normalisiert inkonsistente Werte wie Produktnamen, Kategorien oder Telefonnummern, bevor sie in Workflows oder KI landen.🤖 Daten für Machine Learning vorbereiten
Bereinigt und strukturiert historische Inhalte und Anhänge, um hochwertige Trainingsdaten für KI-Modelle zu generieren – innerhalb oder außerhalb von Zendesk.🧭 Tickets anhand strukturierter Inhalte routen
Nutzt extrahierte Infos wie Abteilung, Sprache oder Standort, um Tickets dem richtigen Team zuzuweisen oder eigene Automatisierungen auszulösen.🪄 Tickets anreichern, bevor Agents loslegen
Befüllt Felder automatisch mit vorverarbeiteten Daten aus E-Mails oder Anhängen, damit Agents sofort helfen können – ohne herunterladen oder Copy-Paste.📨 Brücke zu Legacy-Systemen schlagen
Synchronisiert sogar Tools ohne API, indem ihr DOCX-, Excel- oder CSV-Dateien per E-Mail schickt. Knots verarbeitet sie und aktualisiert Zendesk oder angeschlossene Plattformen in Echtzeit.
Startet eure Data-Preprocessing-Reise mit Knots
Strukturierte, validierte Daten sind die Grundlage für zuverlässige Automatisierung und erfolgreiche KI-Projekte.
Sprecht mit unserem Team oder schaut euch die Apps an, um loszulegen.
Data Preprocessing – Häufig gestellte Fragen
Was ist Data Preprocessing?
Wozu dient Data Preprocessing?
Welche Schritte gehören zum Data Preprocessing?
Warum ist Data Preprocessing wichtig für Automatisierung und KI?
Was sind gängige Techniken im Data Preprocessing?
- Data Cleaning (Duplikate entfernen, fehlende Werte behandeln)
- Data Transformation (Skalierung, Normalisierung)
- Feature Extraction (relevante Variablen identifizieren)
- Data Integration (Datensätze kombinieren)
- Data Encoding (Text in numerische Form bringen)